PlantUMLを使ってみる
クラス図を作成したいと思いぐぐったらPlantUMLが推されていたので設定したメモを残す
環境
インストール
brew install graphviz brew install plantuml
VSCodeでPlantUMLの拡張をインストール marketplace.visualstudio.com
使ってみる
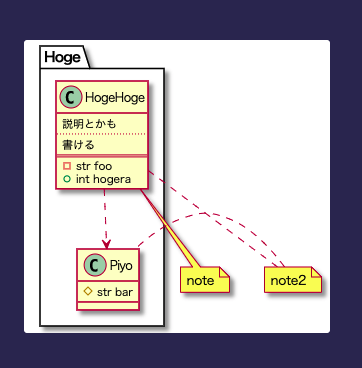
# hoge.pu
# 拡張子は.pu
@startuml
package Hoge {
class HogeHoge {
説明とかも
..
書ける
==
- str foo
+ int hogera
}
class Piyo {
# str bar
}
}
note "note" as N1
note "note2" as N2
HogeHoge ..> Piyo
HogeHoge .. N1
HogeHoge .. N2
N2 .. Piyo
@enduml
option+dでプレビュー表示できる
command+shift+pのコマンドモードでplantumlで色々できることが分かる。便利〜
Nuxt環境構築備忘録
nuxtでなんかやってみよーということでBig Surで環境構築をする。
brewでnodenvをインストール
https://github.com/nodenv/nodenv#installationに則って作業を進める
❯ brew install nodenv
NG!
Version value must be a string; got a NilClass ()というエラーが出て初手からくじかれ、仕方ないので brew upgrade する(これがめっっっっっちゃ長かった、放置していたツケです): https://stackoverflow.com/questions/64821648/homebrew-fails-on-macos-big-sur
再度installコマンドチャレンジするも Killed hoge的なのが出る。これはterminal再起動で解決します
❯ brew install nodenv ❯ nodenv -v nodenv 1.4.0
ようやくnodenv入った🎉
# .zshrcに追記 eval "$(nodenv init -)"
terminalを再起動してからnodenv-doctorで環境がちゃんとできているかチェック
❯ curl -fsSL https://github.com/nodenv/nodenv-installer/raw/master/bin/nodenv-doctor | bash Checking for `nodenv' in PATH: /usr/local/bin/nodenv Checking for nodenv shims in PATH: OK Checking `nodenv install' support: /usr/local/bin/nodenv-install (node-build 4.9.26) Counting installed Node versions: none There aren't any Node versions installed under `/Users/hoge/.nodenv/versions'. You can install Node versions like so: nodenv install 2.2.4 Auditing installed plugins: OK
OK!
nodenvでnodeをインストール
❯ nodenv install 14.15.4 ❯ nodenv global 14.15.4 ❯ nodenv versions * 14.15.4 (set by /Users/hoge/.nodenv/version)
OK!
create-nuxt-app
ja.nuxtjs.org いつ入れたんだか分からないがnpxがいたのでnpxを使う
❯ npx nuxt -v # 初めてだったせいかなにかチェックしていて時間がかかった @nuxt/cli v2.14.12
OK!次!
❯ npx create-nuxt-app nuxt-playground create-nuxt-app v3.5.0 ✨ Generating Nuxt.js project in nuxt-playground ? Project name: nuxt-playground ? Programming language: TypeScript ? Package manager: Npm ? UI framework: Tachyons ? Nuxt.js modules: Axios - Promise based HTTP client ? Linting tools: ESLint, Prettier ? Testing framework: Jest ? Rendering mode: Universal (SSR / SSG) ? Deployment target: Server (Node.js hosting) ? Development tools: jsconfig.json (Recommended for VS Code if you're not using typescript) ? Continuous integration: GitHub Actions (GitHub only) ? What is your GitHub username? hoge ? Version control system: Git
各項目についてはこちら(https://qiita.com/nakazawaken1/items/675b7e16b793330db410)やこちら(https://qiita.com/dama-a/items/c8e9053444b2aecbe5ca) を参考にしました
UI frameworkにTachyonsを選んだのは名前がかっこよかったからです!!!
んで待ってるとnpmで諸々入れてくれる
🎉 Successfully created project nuxt-playground
To get started:
cd nuxt-playground
npm run dev
To build & start for production:
cd nuxt-playground
npm run build
npm run start
To test:
cd nuxt-playground
npm run test
For TypeScript users.
See : https://typescript.nuxtjs.org/cookbook/components/
OK!
起動
❯ cd nuxt-playground ❯ npm run dev
http://localhost:3000/ にアクセス

TSDocメモ
CDKでtypescriptを使い始めて、コメントはTSDocがいいらしいと聞いて軽く調査したメモ
TSDocとは
- Microsoftとかが仕様を作っている規約とパーサ
- TypeScriptで使われる
- JSDocにゆるく基づいてるためJSDocと基本的なフォーマットが一緒
All these tools recognize a syntax that is loosely based on JSDoc
試すには
- リファレンス: TSDoc: @alpha
- TSDoc Playground: TSDoc Playground
メモ
- VSCodeはsyntax highlightingに対応している
- プロジェクト全体にtsdoc付ける、みたいなのはまだなさげ?
- eslintのプラグインはあるのでチェックできる: eslint-plugin-tsdoc - npm
PyAthenaお試しメモ
Athenaのwrapper PyAthenaを試したメモ。10ヶ月前に下書きして放置していたので記憶はもうない SQLAlchemyはノータッチ
インスコ
pip install PyAthena
defaultのdbに対象テーブルが存在する場合
from pyathena import connect cursor = connect(aws_access_key_id='YOUR_ACCESS_KEY_ID', aws_secret_access_key='YOUR_SECRET_ACCESS_KEY', s3_staging_dir='s3://YOUR_S3_BUCKET/path/to/', region_name='ap-northeast-1').cursor() sql = "SELECT * FROM test" cursor.execute(sql) <pyathena.cursor.Cursor object at 0x10e5f6cc0> >>> print(cursor.description) [('hoge', 'varchar', None, None, 2147483647, 0, 'UNKNOWN'), ('fuga', 'varchar', None, None, 2147483647, 0, 'UNKNOWN')] >>> print(cursor.fetchall()) [('piyo', 'piyopiyo'), ('bar', 'barbar')]
- discriptionでカラムの情報が分かる
- AthenaのHistoryにクエリ結果は当然残る
pd.read_csv(io.BytesIO(response['Body'].read()), ...)していて結果ファイルのごみは残らない
任意のdbを作成、そこに存在するテーブルを指定した場合
sql = "SELECT * FROM test2"
>>> cursor.execute(sql)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/a999-373/.pyenv/versions/3.7.1/lib/python3.7/site-packages/pyathena/util.py", line 185, in _wrapper
return wrapped(*args, **kwargs)
File "/Users/a999-373/.pyenv/versions/3.7.1/lib/python3.7/site-packages/pyathena/cursor.py", line 57, in execute
raise OperationalError(query_execution.state_change_reason)
pyathena.error.OperationalError: SYNTAX_ERROR: line 2:12: Table awsdatacatalog.default.test2 does not exist